
Nature:为高维度医学成像设计可临床转化的人工
原文链接: AI 系统,所带来的一些问题和挑战的研究人员提供了一个模板。
2021-12-10
另一种方法是在训练逻辑中限制机器学习算法,确保发生优化步骤以控制感兴趣的人口统计学变量。这类似于多变量回归模型,其中感兴趣的风险因素的影响可以独立于基线人口统计学变量来研究。从技术角度看,这将涉及到在训练循环中插入一个额外的惩罚性损失,并牢记与稍低的模型性能的潜在权衡。例如,Fairlearn 是用于评估传统机器学习模型公平性的流行工具包,并且已经开发了基于 Fairlearn 算法 (FairTorch) 的约束优化,这是在训练过程中整合偏差调整的有希望的探索性尝试。有许多开源工具包可以帮助研究人员确定不同变量和输入流(图像预测,以及诸如性别和种族等变量)的相对重要性。这些技术可能允许开发更公平的机器学习系统,甚至可以发现没有预料到的隐藏偏见。
在2018年美国国家卫生研究院的路线图中,缺乏特定于医学成像的架构被认为是一项关键挑战。我们进一步延伸,提出训练这些架构的方法,对这些系统将转化为现实方面发挥着重要作用。我们认为,下一代的高维医学成像AI 将需要对更丰富、更有背景意义的目标进行训练,而不是简单的分类标签。
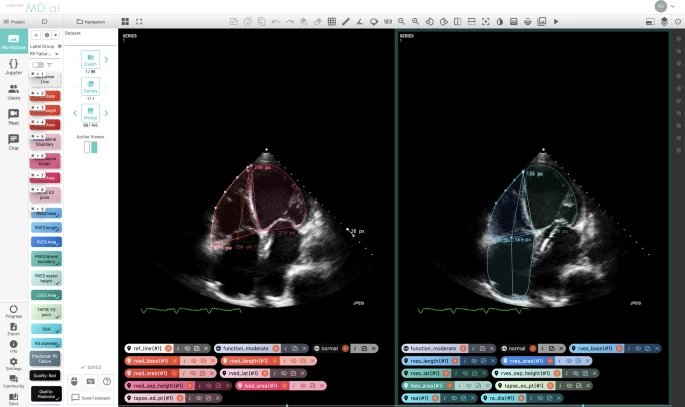
尽管计算架构和获取高质量数据是构建良好模型的关键,但为高维成像模式开发可转换的机器学习系统方面还需要努力,以更好地代表数据的 "视频 "性质。此外还需要在模型开发的早期阶段建立有助于解决偏见、不确定性和可解释性的功能。对医学成像和人工智能的质疑是有益的,而且在大多数情况下具有一定道理。
2021-12-09
神经网络首先通过执行一组 "代理任务 "来学习 "描述 "作为输入的成像扫描。例如,通过让网络像拼图一样 "重新组合 "输入的扫描数据,它们可以被训练成 "理解 "在各种病理和生理状态下哪些解剖结构是相互一致的。将成像扫描的数据与放射学报告配对是另一个有趣的策略,基于胸部X射线的人工智能系统取得了相当大的成功。
自动去识别方法或脚本经常被提及的一个缺点是受保护的健康信息有可能被 "刻录 "在影像文件中。尽管有DICOM标准,但制造商的不同,使得难以通过 MIRC 临床试验处理器等工具来生成简单的规则,以屏蔽可能位于受保护健康信息的区域。我们建议使用一个简单的机器学习系统来屏蔽 "烧录 "的受保护健康信息。
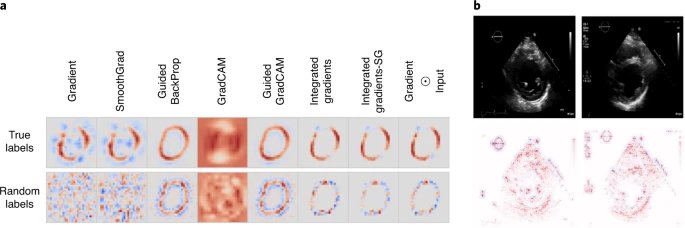
图3:事后模型解释的误导性。
正如 Sensoy 等人所描述的那样,即使在不正确的情况下,使用标准方法训练的机器学习模型也可以非常自信。左图:当一个数字被旋转180°时,系统自信地分配了一个从 "1 "到 "7 "的标签。右图:然而,用考虑分类不确定性的方法,系统会分配一个不确定性分数,可以帮助提醒临床医生潜在的错误预测。
我们预计,在可预见的未来,可用的高质量 "AI-ready "注释的医学数据集将仍然不能满足需求。回过头来分配临床事实标签需要临床专家投入大量的时间,而且将多机构的数据汇总起来公开发布也存在很大的障碍。除了需要以在硬放射学真实标签上训练的模型为特征的“诊断人工智能”之外,还需要根据潜在的更复杂的临床综合结果目标训练的 "疾病预测人工智能 "。具有标准化的图像采集协议和临床基本事实裁决的前瞻性数据收集,是构建具有配对临床结果的大规模多中心成像数据集的必要步骤。
这可以通过建立 "融合网络 "来实现,其中表格数据被合并到基于图像或视频的神经网络中,或其他具有相同基本目标的更先进的方法(生成组合数据的低维表示的自动编码器)。即使没有将人口统计学输入纳入高维视觉网络,研究小组通过比较不同性别、种族、地域和收入群体的表现来审核他们的模型也很重要。
用基于图像和视频的机器学习来扩展传统的生存模型,可以对组织切片或医学成像扫描中的特征的预后价值提供强有力的洞察力。例如,将Cox比例损失函数的扩展整合到传统的神经网络架构中,使得仅从组织病理学切片中预测癌症结果成为可能。我们不主张使用此类视觉网络来规定如何进行护理,而是主张将其用作标记临床医生遗漏晚期恶性肿瘤特征的病例的方法。